Disaster recovery (DR) involves a set of policies and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster. Disaster recovery focuses on the IT or technology systems supporting critical business functions, as opposed to business continuity, which involves keeping all essential aspects of a business functioning despite significant disruptive events. Disaster recovery is therefore a subset of business continuity.
History
Disaster recovery developed in the mid- to late 1970s as computer center managers began to recognize the dependence of their organizations on their computer systems. At that time, most systems were batch-oriented mainframes which in many cases could be down for a number of days before significant damage would be done to the organization.
As awareness of the potential business disruption that would follow an IT-related disaster, the disaster recovery industry developed to provide backup computer centers, with Sun Information Systems (which later became Sungard Availability Services) becoming the first major US commercial hot site vendor, established in 1978 in Philadelphia.
During the 1980s and 90s, customer awareness and industry both grew rapidly, driven by the advent of open systems and real-time processing which increased the dependence of organizations on their IT systems. Regulations mandating business continuity and disaster recovery plans for organizations in various sectors of the economy, imposed by the authorities and by business partners, increased the demand and led to the availability of commercial disaster recovery services, including mobile data centers delivered to a suitable recovery location by truck.
With the rapid growth of the Internet through the late 1990s and into the 2000s, organizations of all sizes became further dependent on the continuous availability of their IT systems, with some organizations setting objectives of 2, 3, 4 or 5 nines (99.999%) availability of critical systems. This increasing dependence on IT systems, as well as increased awareness from large-scale disasters such as tsunami, earthquake, flood, and volcanic eruption, spawned disaster recovery-related products and services, ranging from high-availability solutions to hot-site facilities. Improved networking meant critical IT services could be served remotely, hence on-site recovery became less important.
The meteoric rise of cloud computing since 2010 continues that trend: nowadays, it matters even less where computing services are physically served, just so long as the network itself is sufficiently reliable (a separate issue, and less of a concern since modern networks are highly resilient by design). 'Recovery as a Service' (RaaS) is one of the security features or benefits of cloud computing being promoted by the Cloud Security Alliance.
Classification of disasters
Disasters can be classified into two broad categories. The first is natural disasters such as floods, hurricanes, tornadoes or earthquakes. While preventing a natural disaster is very difficult, risk management measures such as avoiding disaster-prone situations and good planning can help. The second category is man made disasters, such as hazardous material spills, infrastructure failure, bio-terrorism, and disastrous IT bugs or failed change implementations. In these instances, surveillance, testing and mitigation planning are invaluable.
Importance of disaster recovery planning
Recent research supports the idea that implementing a more holistic pre-disaster planning approach is more cost-effective in the long run. Every $1 spent on hazard mitigation(such as a disaster recovery plan)saves society $4 in response and recovery costs.
As IT systems have become increasingly critical to the smooth operation of a company, and arguably the economy as a whole, the importance of ensuring the continued operation of those systems, and their rapid recovery, has increased. For example, of companies that had a major loss of business data, 43% never reopen and 29% close within two years. As a result, preparation for continuation or recovery of systems needs to be taken very seriously. This involves a significant investment of time and money with the aim of ensuring minimal losses in the event of a disruptive event.
Control measures
Control measures are steps or mechanisms that can reduce or eliminate various threats for organizations. Different types of measures can be included in disaster recovery plan (DRP).
Disaster recovery planning is a subset of a larger process known as business continuity planning and includes planning for resumption of applications, data, hardware, electronic communications (such as networking) and other IT infrastructure. A business continuity plan (BCP) includes planning for non-IT related aspects such as key personnel, facilities, crisis communication and reputation protection, and should refer to the disaster recovery plan (DRP) for IT related infrastructure recovery / continuity.
IT disaster recovery control measures can be classified into the following three types:
- Preventive measures - Controls aimed at preventing an event from occurring.
- Detective measures - Controls aimed at detecting or discovering unwanted events.
- Corrective measures - Controls aimed at correcting or restoring the system after a disaster or an event.
Good disaster recovery plan measures dictate that these three types of controls be documented and exercised regularly using so-called "DR tests".
Strategies
Prior to selecting a disaster recovery strategy, a disaster recovery planner first refers to their organization's business continuity plan which should indicate the key metrics of recovery point objective (RPO) and recovery time objective (RTO) for various business processes (such as the process to run payroll, generate an order, etc.). The metrics specified for the business processes are then mapped to the underlying IT systems and infrastructure that support those processes.
Incomplete RTOs and RPOs can quickly derail a disaster recovery plan. Every item in the DR plan requires a defined recovery point and time objective, as failure to create them may lead to significant problems that can extend the disaster’s impact. Once the RTO and RPO metrics have been mapped to IT infrastructure, the DR planner can determine the most suitable recovery strategy for each system. The organization ultimately sets the IT budget and therefore the RTO and RPO metrics need to fit with the available budget. While most business unit heads would like zero data loss and zero time loss, the cost associated with that level of protection may make the desired high availability solutions impractical. A cost-benefit analysis often dictates which disaster recovery measures are implemented.
Some of the most common strategies for data protection include:
- backups made to tape and sent off-site at regular intervals
- backups made to disk on-site and automatically copied to off-site disk, or made directly to off-site disk
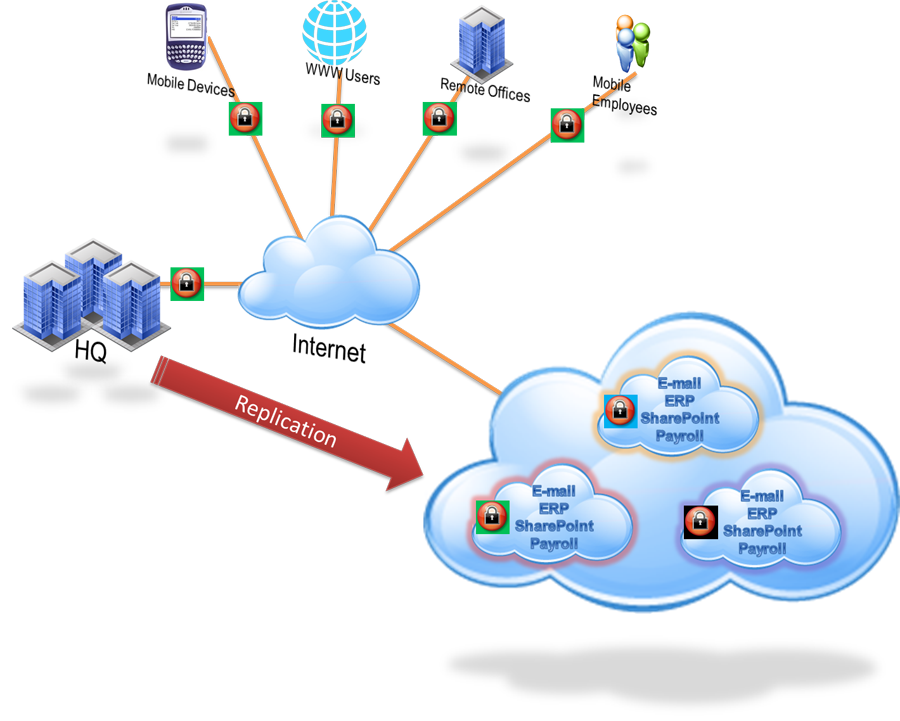
- replication of data to an off-site location, which overcomes the need to restore the data (only the systems then need to be restored or synchronized), often making use of storage area network (SAN) technology
- Private Cloud solutions which replicate the management data (VMs, Templates and disks) into the storage domains which are part of the private cloud setup. These management data are configured as an xml representation called OVF (Open Virtualization Format), and can be restored from the Data Base once a disaster occurs. For example, Disaster Recovery with oVirt[
- Hybrid Cloud solutions that replicate both on-site and to off-site data centers. These solutions provide the ability to instantly fail-over to local on-site hardware, but in the event of a physical disaster, servers can be brought up in the cloud data centers as well. Examples include Quorom, rCloud from Persistent Systems or EverSafe.
- the use of high availability systems which keep both the data and system replicated off-site, enabling continuous access to systems and data, even after a disaster (often associated with cloud storage)
In many cases, an organization may elect to use an outsourced disaster recovery provider to provide a stand-by site and systems rather than using their own remote facilities, increasingly via cloud computing.
In addition to preparing for the need to recover systems, organizations also implement precautionary measures with the objective of preventing a disaster in the first place. These may include:
- local mirrors of systems and/or data and use of disk protection technology such as RAID
- surge protectors — to minimize the effect of power surges on delicate electronic equipment
- use of an uninterruptible power supply (UPS) and/or backup generator to keep systems going in the event of a power failure
- fire prevention/mitigation systems such as alarms and fire extinguishers
- anti-virus software and other security measures