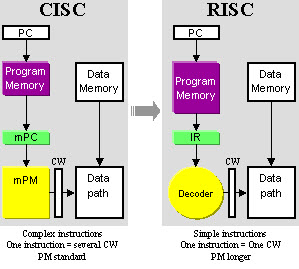
Complex instruction set computing (CISC) is a processor design where single instructions can execute several low-level operations (such as a load from memory, an arithmetic operation, and a memory store) or are capable of multi-step operations or addressing modes within single instructions. The term was retroactively coined in contrast to reduced instruction set computer (RISC) and has therefore become something of an umbrella term for everything that is not RISC, i.e. everything from large and complex mainframes to simplistic microcontrollers where memory load and store operations are not separated from arithmetic instructions.
A modern RISC processor can therefore be much more complex than, say, a modern microcontroller using a CISC-labeled instruction set, especially in terms of implementation (electronic circuit complexity), but also in terms of the number of instructions or the complexity of their encoding patterns. The only differentiating characteristic (nearly) "guaranteed" is the fact that most RISC designs use uniform instruction length for (almost) all instructions and employ strictly separate load/store-instructions.
Examples of instruction set architectures that have been retroactively labeled CISC are System/360 through z/Architecture, the PDP-11 and VAX architectures, Data General Nova and many others. Well known microprocessors and microcontrollers that have also been labeled CISC in many academic publications include the Motorola 6800, 6809 and 68000-families; the Intel 8080, iAPX432 and x86-family; the Zilog Z80, Z8 and Z8000-families; the National Semiconductor 32016 and NS320xx-line; the MOS Technology 6502-family; the Intel 8051-family; and others.
Some designs have been regarded as borderline cases by some writers. For instance, the Microchip Technology PIC has been labeled RISC in some circles and CISC in others and the 6502 and 6809 have both been described as "RISC-like", although they have complex addressing modes as well as arithmetic instructions that access memory, contrary to the RISC-principles.
Incitements and benefits
Before the RISC philosophy became prominent, many computer architects tried to bridge the so-called semantic gap, i.e. to design instruction sets that directly supported high-level programming constructs such as procedure calls, loop control, and complex addressing modes, allowing data structure and array accesses to be combined into single instructions. Instructions are also typically highly encoded in order to further enhance the code density. The compact nature of such instruction sets results in smaller program sizes and fewer (slow) main memory accesses, which at the time (early 1960s and onwards) resulted in a tremendous savings on the cost of computer memory and disc storage, as well as faster execution. It also meant good programming productivity even in assembly language, as high level languages such as Fortran or Algol were not always available or appropriate (microprocessors in this category are sometimes still programmed in assembly language for certain types of critical applications.
New instructions
In the 1970s, analysis of high level languages indicated some complex machine language implementations and it was determined that new instructions could improve performance. Some instructions were added that were never intended to be used in assembly language but fit well with compiled high level languages. Compilers were updated to take advantage of these instructions. The benefits of semantically rich instructions with compact encodings can be seen in modern processors as well, particularly in the high performance segment where caches are a central component (as opposed to most embedded systems). This is because these fast, but complex and expensive, memories are inherently limited in size, making compact code beneficial. Of course, the fundamental reason they are needed is that main memories (i.e. dynamic RAM today) remain slow compared to a (high performance) CPU-core.
Design issues
While many designs achieved the aim of higher throughput at lower cost and also allowed high-level language constructs to be expressed by fewer instructions, it was observed that this was not always the case. For instance, low-end versions of complex architectures (i.e. using less hardware) could lead to situations where it was possible to improve performance by not using a complex instruction (such as a procedure call or enter instruction), but instead using a sequence of simpler instructions.
One reason for this was that architects (microcode writers) sometimes "over-designed" assembler language instructions, i.e. including features which were not possible to implement efficiently on the basic hardware available. This could, for instance, be "side effects" (above conventional flags), such as the setting of a register or memory location that was perhaps seldom used; if this was done via ordinary (non duplicated) internal buses, or even the external bus, it would demand extra cycles every time, and thus be quite inefficient.
Even in balanced high performance designs, highly encoded and (relatively) high-level instructions could be complicated to decode and execute efficiently within a limited transistor budget. Such architectures therefore required a great deal of work on the part of the processor designer in cases where a simpler, but (typically) slower, solution based on decode tables and/or microcode sequencing is not appropriate. At a time when transistors and other components were a limited resource, this also left fewer components and less opportunity for other types of performance optimizations.
The RISC idea
The circuitry that performs the actions defined by the microcode in many (but not all) CISC processors is, in itself, a processor which in many ways is reminiscent in structure to very early CPU designs. In the early 1970s, this gave rise to ideas to return to simpler processor designs in order to make it more feasible to cope without (then relatively large and expensive) ROM tables and/or PLA structures for sequencing and/or decoding. The first (retroactively) RISC-labeled processor (IBM 801 - IBM's Watson Research Center, mid-1970s) was a tightly pipelined simple machine originally intended to be used as an internal microcode kernel, or engine, in CISC designs, but also became the processor that introduced the RISC idea to a somewhat larger public. Simplicity and regularity also in the visible instruction set would make it easier to implement overlapping processor stages (pipelining) at the machine code level (i.e. the level seen by compilers). However, pipelining at that level was already used in some high performance CISC "supercomputers" in order to reduce the instruction cycle time (despite the complications of implementing within the limited component count and wiring complexity feasible at the time). Internal microcode execution in CISC processors, on the other hand, could be more or less pipelined depending on the particular design, and therefore more or less akin to the basic structure of RISC processors.
Superscalar
In a more modern context, the complex variable length encoding used by some of the typical CISC architectures makes it complicated, but still feasible, to build a superscalar implementation of a CISC programming model directly; the in-order superscalar original Pentium and the out-of-order superscalar Cyrix 6x86 are well known examples of this. The frequent memory accesses for operands of a typical CISC machine may limit the instruction level parallelism that can be extracted from the code, although this is strongly mediated by the fast cache structures used in modern designs, as well as by other measures. Due to inherently compact and semantically rich instructions, the average amount of work performed per machine code unit (i.e. per byte or bit) is higher for a CISC than a RISC processor, which may give it a significant advantage in a modern cache based implementation.
Transistors for logic, PLAs, and microcode are no longer scarce resources; only large high-speed cache memories are limited by the maximum number of transistors today. Although complex, the transistor count of CISC decoders do not grow exponentially like the total number of transistors per processor (the majority typically used for caches). Together with better tools and enhanced technologies, this has led to new implementations of highly encoded and variable length designs without load-store limitations (i.e. non-RISC). This governs re-implementations of older architectures such as the ubiquitous x86 (see below) as well as new designs for microcontrollers for embedded systems, and similar uses. The superscalar complexity in the case of modern x86 was solved by converting instructions into one or more micro-operations and dynamically issuing those micro-operations, i.e. indirect and dynamic superscalar execution; the Pentium Pro and AMD K5 are early examples of this. It allows a fairly simple superscalar design to be located after the (fairly complex) decoders (and buffers), giving, so to speak, the best of both worlds in many respects.
CISC and RISC terms
The terms CISC and RISC have become less meaningful with the continued evolution of both CISC and RISC designs and implementations. The first highly (or tightly) pipelined x86 implementations, the 486 designs from Intel, AMD, Cyrix, and IBM, supported every instruction that their predecessors did, but achieved maximum efficiency only on a fairly simple x86 subset that was only a little more than a typical RISC instruction set (i.e. without typical RISC load-store limitations). The Intel P5 Pentium generation was a superscalar version of these principles. However, modern x86 processors also (typically) decode and split instructions into dynamic sequences of internally buffered micro-operations, which not only helps execute a larger subset of instructions in a pipelined (overlapping) fashion, but also facilitates more advanced extraction of parallelism out of the code stream, for even higher performance.
Contrary to popular simplifications (present also in some academic texts), not all CISCs are microcoded or have "complex" instructions. As CISC became a catch-all term meaning anything that's not a load-store (RISC) architecture, it's not the number of instructions, nor the complexity of the implementation or of the instructions themselves, that define CISC, but the fact that arithmetic instructions also perform memory accesses. Compared to a small 8-bit CISC processor, a RISC floating-point instruction is complex. CISC does not even need to have complex addressing modes; 32 or 64-bit RISC processors may well have more complex addressing modes than small 8-bit CISC processors.
A PDP-10, a PDP-8, an Intel 386, an Intel 4004, a Motorola 68000, a System z mainframe, a Burroughs B5000, a VAX, a Zilog Z80000, and a MOS Technology 6502 all vary wildly in the number, sizes, and formats of instructions, the number, types, and sizes of registers, and the available data types. Some have hardware support for operations like scanning for a substring, arbitrary-precision BCD arithmetic, or transcendental functions, while others have only 8-bit addition and subtraction. But they are all in the CISC category because they have "load-operate" instructions that load and/or store memory contents within the same instructions that perform the actual calculations. For instance, the PDP-8, having only 8 fixed-length instructions and no microcode at all, is a CISC because of how the instructions work, PowerPC, which has over 230 instructions (more than some VAXes) and complex internals like register renaming and a reorder buffer is a RISC, while Minimal CISC has 8 instructions, but is clearly a CISC because it combines memory access and computation in the same instructions.
Some of the problems and contradictions in this terminology will perhaps disappear as more systematic terms, such as (non) load/store, become more popular and eventually replace the imprecise and slightly counter-intuitive RISC/CISC terms.