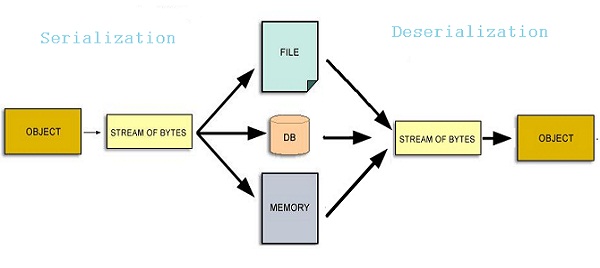
In computer science, in the context of data storage, serialization is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer, or transmitted across a network connection link) and reconstructed later in the same or another computer environment. When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of object-oriented objects does not include any of their associated methods with which they were previously inextricably linked.
This process of serializing an object is also called marshalling an object. The opposite operation, extracting a data structure from a series of bytes, is deserialization (which is also called unmarshalling).
Uses
- A method of transferring data through the wires (messaging).
- A method of storing data (in databases, on hard disk drives).
- A method of remote procedure calls, e.g., as in SOAP.
- A method for distributing objects, especially in component-based software engineering such as COM, CORBA, etc.
- A method for detecting changes in time-varying data.
For some of these features to be useful, architecture independence must be maintained. For example, for maximal use of distribution, a computer running on a different hardware architecture should be able to reliably reconstruct a serialized data stream, regardless of endianness. This means that the simpler and faster procedure of directly copying the memory layout of the data structure cannot work reliably for all architectures. Serializing the data structure in an architecture independent format means preventing the problems of byte ordering, memory layout, or simply different ways of representing data structures in different programming languages.
Inherent to any serialization scheme is that, because the encoding of the data is by definition serial, extracting one part of the serialized data structure requires that the entire object be read from start to end, and reconstructed. In many applications this linearity is an asset, because it enables simple, common I/O interfaces to be utilized to hold and pass on the state of an object. In applications where higher performance is an issue, it can make sense to expend more effort to deal with a more complex, non-linear storage organization.
Even on a single machine, primitive pointer objects are too fragile to save because the objects to which they point may be reloaded to a different location in memory. To deal with this, the serialization process includes a step called unswizzling or pointer unswizzling, where direct pointer references are converted to references based on name or position. The deserialization process includes an inverse step called pointer swizzling.
Since both serializing and deserializing can be driven from common code (for example, the Serialize function in Microsoft Foundation Classes), it is possible for the common code to do both at the same time, and thus, 1) detect differences between the objects being serialized and their prior copies, and 2) provide the input for the next such detection. It is not necessary to actually build the prior copy because differences can be detected on the fly. The technique is called differential execution. It is useful in the programming of user interfaces whose contents are time-varying — graphical objects can be created, removed, altered, or made to handle input events without necessarily having to write separate code to do those things.
Consequences
Serialization breaks the opacity of an abstract data type by potentially exposing private implementation details. Trivial implementations which serialize all data members may violate encapsulation.
To discourage competitors from making compatible products, publishers of proprietary software often keep the details of their programs' serialization formats a trade secret. Some deliberately obfuscate or even encrypt the serialized data. Yet, interoperability requires that applications be able to understand each other's serialization formats. Therefore, remote method call architectures such as CORBA define their serialization formats in detail.
Many institutions, such as archives and libraries, attempt to future proof their backup archives—in particular, database dumps—by storing them in some relatively human-readable serialized format.
Serialization formats
Main article: Comparison of data serialization formats
The Xerox Network Systems Courier technology in the early 1980s influenced the first widely adopted standard. Sun Microsystems published the External Data Representation (XDR) in 1987.
In the late 1990s, a push to provide an alternative to the standard serialization protocols started: XML was used to produce a human readable text-based encoding. Such an encoding can be useful for persistent objects that may be read and understood by humans, or communicated to other systems regardless of programming language. It has the disadvantage of losing the more compact, byte-stream-based encoding, but by this point larger storage and transmission capacities made file size less of a concern than in the early days of computing. Binary XML had been proposed as a compromise which was not readable by plain-text editors, but was more compact than regular XML. In the 2000s, XML was often used for asynchronous transfer of structured data between client and server in Ajax web applications.
JSON is a more lightweight plain-text alternative to XML which is also commonly used for client-server communication in web applications. JSON is based on JavaScript syntax, but is supported in other programming languages as well.
Another alternative, YAML, is effectively a superset of JSON and includes features that make it more powerful for serialization, more "human friendly," and potentially more compact. These features include a notion of tagging data types, support for non-hierarchical data structures, the option to structure data with indentation, and multiple forms of scalar data quoting.
Another human-readable serialization format is the property list format used in NeXTSTEP, GNUstep, and OS X Cocoa.
For large volume scientific datasets, such as satellite data and output of numerical climate, weather, or ocean models, specific binary serialization standards have been developed, e.g. HDF, netCDF and the older GRIB.
Programming language support
Several object-oriented programming languages directly support object serialization (or object archival), either by syntactic sugar elements or providing a standard interface for doing so. Some of these programming languages are Ruby, Smalltalk, Python, PHP, Objective-C, Java, and the .NET family of languages. There are also libraries available that add serialization support to languages that lack native support for it.
JavaJava provides automatic serialization which requires that the object be marked by implementing the java.io.Serializable interface. Implementing the interface marks the class as "okay to serialize", and Java then handles serialization internally. There are no serialization methods defined on the Serializable interface, but a serializable class can optionally define methods with certain special names and signatures that if defined, will be called as part of the serialization/deserialization process. The language also allows the developer to override the serialization process more thoroughly by implementing another interface, the Externalizable interface, which includes two special methods that are used to save and restore the object's state. There are three primary reasons why objects are not serializable by default and must implement the Serializable interface to access Java's serialization mechanism. Firstly, not all objects capture useful semantics in a serialized state. For example, a Thread object is tied to the state of the current JVM. There is no context in which a deserialized Thread object would maintain useful semantics. Secondly, the serialized state of an object forms part of its classes' compatibility contract. Maintaining compatibility between versions of serializable classes requires additional effort and consideration. Therefore, making a class serializable needs to be a deliberate design decision and not a default condition. Lastly, serialization allows access to non-transient private members of a class that are not otherwise accessible. Classes containing sensitive information (for example, a password) should not be serializable nor externalizable. The standard encoding method uses a simple translation of the fields into a byte stream. Primitives as well as non-transient, non-static referenced objects are encoded into the stream. Each object that is referenced by the serialized object and not marked as transient must also be serialized; and if any object in the complete graph of non-transient object references is not serializable, then serialization will fail. The developer can influence this behavior by marking objects as transient, or by redefining the serialization for an object so that some portion of the reference graph is truncated and not serialized. It is possible to serialize Java objects through JDBC and store them into a database.[citation needed] While Swing components do implement the Serializable interface, they are not portable between different versions of the Java Virtual Machine. As such, a Swing component, or any component which inherits it, may be serialized to an array of bytes, but it is not guaranteed that this storage will be readable on another machine..NET Framework.NET Framework has several serializers designed by Microsoft. There are also many serializers by third parties. More than a dozen serializers are discussed and tested here.[5] and here[6] The list is constantly growing.CFMLCFML allows data structures to be serialized to WDDX with the <cfwddx> tag and to JSON with the SerializeJSON() function.OCamlOCaml's standard library provides marshalling through the Marshal module (its documentation) and the Pervasives functions output_value and input_value. While OCaml programming is statically type-checked, uses of the Marshal module may break type guarantees, as there is no way to check whether an unmarshalled stream represents objects of the expected type. In OCaml it is difficult to marshal a function or a data structure which contains a function (e.g. an object which contains a method), because executable code in functions cannot be transmitted across different programs. (There is a flag to marshal the code position of a function but it can only be unmarshalled in exactly the same program). The standard marshalling functions can preserve sharing and handle cyclic data, which can be configured by a flag.PerlSeveral Perl modules available from CPAN provide serialization mechanisms, including Storable , JSON::XS and FreezeThaw. Storable includes functions to serialize and deserialize Perl data structures to and from files or Perl scalars. In addition to serializing directly to files, Storable includes the freeze function to return a serialized copy of the data packed into a scalar, and thaw to deserialize such a scalar. This is useful for sending a complex data structure over a network socket or storing it in a database. When serializing structures with Storable, there are network safe functions that always store their data in a format that is readable on any computer at a small cost of speed. These functions are named nstore, nfreeze, etc. There are no "n" functions for deserializing these structures — the regular thaw and retrieve deserialize structures serialized with the "n" functions and their machine-specific equivalents.C and C++C and C++ do not provide direct support for serialization. It is however possible to write custom serialization functions, since both languages support writing binary data. Besides, compiler-based solutions, such as the ODB ORM system for C++, are capable of automatically producing serialization code with few or no modifications to class declarations. Other popular serialization frameworks are Boost.Serialization[7] from the Boost Framework, the S11n framework,[8] and Cereal.[9] MFC framework (Microsoft) also provides serialization methodology as part of its Document-View architecture. The C++ Middleware Writer automates the creation of serialization functions.PythonThe core general serialization mechanism is the pickle standard library module. It is a cross-version customisable but unsafe (not secure against erroneous or malicious data) serialization format. The standard library also includes modules serializing to standard data formats: json (with built-in support for basic scalar and collection types and able to support arbitrary types via encoding and decoding hooks) and XML-encoded property lists. (plistlib), limited to plist-supported types (numbers, strings, booleans, tuples, lists, dictionaries, datetime and binary blobs). Finally, it is recommended that an object's __repr__ be evaluable in the right environment, making it a rough match for Common Lisp's print-object.PHPPHP originally implemented serialization through the built-in serialize() and unserialize() functions.[10] PHP can serialize any of its data types except resources (file pointers, sockets, etc.). The built-in unserialize() function is often dangerous when used on completely untrusted data.[11] For objects, there are two "magic methods" that can be implemented within a class — __sleep() and __wakeup() — that are called from within serialize() and unserialize(), respectively, that can clean up and restore an object. For example, it may be desirable to close a database connection on serialization and restore the connection on deserialization; this functionality would be handled in these two magic methods. They also permit the object to pick which properties are serialized. Since PHP 5.1, there is an object-oriented serialization mechanism for objects, the Serializable interface.[12]RR has the function dput which writes an ASCII text representation of an R object to a file or connection. A representation can be read from a file using dget.[13]REBOLREBOL will serialize to file (save/all) or to a string! (mold/all). Strings and files can be deserialized using the polymorphic load function. RProtoBuf provides cross-language data serialization in R, using protocol buffers.[14]RubyRuby includes the standard module Marshal with 2 methods dump and load, akin to the standard Unix utilities dump and restore. These methods serialize to the standard class String, that is, they effectively become a sequence of bytes. Some objects cannot be serialized (doing so would raise a TypeError exception): bindings, procedure objects, instances of class IO, singleton objects and interfaces. If a class requires custom serialization (for example, it requires certain cleanup actions done on dumping / restoring), it can be done by implementing 2 methods: _dump and _load. The instance method _dump should return a String object containing all the information necessary to reconstitute objects of this class and all referenced objects up to a maximum depth given as an integer parameter (a value of -1 implies that depth checking should be disabled). The class method _load should take a String and return an object of this class.SmalltalkIn general, non-recursive and non-sharing objects can be stored and retrieved in a human readable form using the storeOn:/readFrom: protocol. The storeOn: method generates the text of a Smalltalk expression which - when evaluated using readFrom: - recreates the original object. This scheme is special, in that it uses a procedural description of the object, not the data itself. It is therefore very flexible, allowing for classes to define more compact representations. However, in its original form, it does not handle cyclic data structures or preserve the identity of shared references (i.e. two references a single object will be restored as references to two equal, but not identical copies). For this, various portable and non-portable alternatives exist. Some of them are specific to a particular Smalltalk implementation or class library. There are several ways in Squeak Smalltalk to serialize and store objects. The easiest and most used are storeOn:/readFrom: and binary storage formats based on SmartRefStream serializers. In addition, bundled objects can be stored and retrieved using ImageSegments. Both provide a so-called "binary-object storage framework", which support serialization into and retrieval from a compact binary form. Both handle cyclic, recursive and shared structures, storage/retrieval of class and metaclass info and include mechanisms for "on the fly" object migration (i.e. to convert instances which were written by an older version of a class with a different object layout). The APIs are similar (storeBinary/readBinary), but the encoding details are different, making these two formats incompatible. However, the Smalltalk/X code is open source and free and can be loaded into other Smalltalks to allow for cross-dialect object interchange. Object serialization is not part of the ANSI Smalltalk specification. As a result, the code to serialize an object varies by Smalltalk implementation. The resulting binary data also varies. For instance, a serialized object created in Squeak Smalltalk cannot be restored in Ambrai Smalltalk. Consequently, various applications that do work on multiple Smalltalk implementations that rely on object serialization cannot share data between these different implementations. These applications include the MinneStore object database [1] and some RPC packages. A solution to this problem is SIXX [2], which is a package for multiple Smalltalks that uses an XML-based format for serialization.LispGenerally a Lisp data structure can be serialized with the functions "read" and "print". A variable foo containing, for example, a list of arrays would be printed by (print foo). Similarly an object can be read from a stream named s by (read s). These two parts of the Lisp implementation are called the Printer and the Reader. The output of "print" is human readable; it uses lists demarked by parentheses, for example: (4 2.9 "x" y). In many types of Lisp, including Common Lisp, the printer cannot represent every type of data because it is not clear how to do so. In Common Lisp for example the printer cannot print CLOS objects. Instead the programmer may write a method on the generic function print-object, this will be invoked when the object is printed. This is somewhat similar to the method used in Ruby. Lisp code itself is written in the syntax of the reader, called read syntax. Most languages use separate and different parsers to deal with code and data, Lisp only uses one. A file containing lisp code may be read into memory as a data structure, transformed by another program, then possibly executed or written out, such as in a read–eval–print loop. Not all readers/writers support cyclic, recursive or shared structures.HaskellIn Haskell, serialization is supported for types that are members of the Read and Show type classes. Every type that is a member of the Read type class defines a function that will extract the data from the string representation of the dumped data. The Show type class, in turn, contains the show function from which a string representation of the object can be generated. The programmer need not define the functions explicitly—merely declaring a type to be deriving Read or deriving Show, or both, can make the compiler generate the appropriate functions for many cases (but not all: function types, for example, cannot automatically derive Show or Read). The auto-generated instance for Show also produces valid source code, so the same Haskell value can be generated by running the code produced by show in, for example, a Haskell interpreter.[15] For more efficient serialization, there are haskell libraries that allow high-speed serialization in binary format, e.g. binary.Windows PowerShellWindows PowerShell implements serialization through the built-in cmdlet Export-CliXML. Export-CliXML serializes .NET objects and stores the resulting XML in a file. To reconstitute the objects, use the Import-CliXML cmdlet, which generates a deserialized object from the XML in the exported file. Deserialized objects, often known as "property bags" are not live objects; they are snapshots that have properties, but no methods. Two dimensional data structures can also be (de)serialized in CSV format using the built-in cmdlets Import-CSV and Export-CSV.JuliaJulia implements serialization through the serialize() / deserialize() modules,[16] intended to work within the same version of Julia, and/or instance of the same system image.[17] The HDF5.jl package offers a more stable alternative, using a documented format and common library with wrappers for different languages,[18] while the default serialization format is suggested to have been designed rather with maximal performance for network communication in mind.[19]