Memcached (pronunciation: mem-cash-dee) is a general-purpose distributed memory caching system. It is often used to speed up dynamic database-driven websites by caching data and objects in RAM to reduce the number of times an external data source (such as a database or API) must be read.
Memcached is free and open-source software, licensed under the Revised BSD license. Memcached runs on Unix-like operating systems (at least Linux and OS X) and on Microsoft Windows. It depends on the libevent library.
Memcached's APIs provide a very large hash table distributed across multiple machines. When the table is full, subsequent inserts cause older data to be purged in least recently used (LRU) order. Applications using Memcached typically layer requests and additions into RAM before falling back on a slower backing store, such as a database.
The size of this hash table is often very large. It is limited to available memory across all the servers in the cluster of servers in a data centre. Where high volume, wide audience web publishing requires it, this may stretch to many gigabytes. Memcached can be equally valuable for situations where either the number of requests for content is high, or the cost of generating a particular piece of content is high.
Memcached was originally developed by Danga Interactive for LiveJournal, but is now used by many other systems, including MocoSpace,[5] YouTube,[6] Reddit,[7] Survata,[8] Zynga,[9] Facebook,[10][11][12] Orange,[13] Twitter,[14] Tumblr[15] and Wikipedia.[16] Engine Yard and Jelastic are using Memcached as part of their platform as a service technology stack[17][18] and Heroku offers several Memcached services[19] as part of their platform as a service. Google App Engine, AppScale, Microsoft Azure and Amazon Web Services also offer a Memcached service through an API.
History
Memcached was first developed by Brad Fitzpatrick for his website LiveJournal, on May 22, 2003. It was originally written in Perl, then later rewritten in C by Anatoly Vorobey, then employed by LiveJournal.
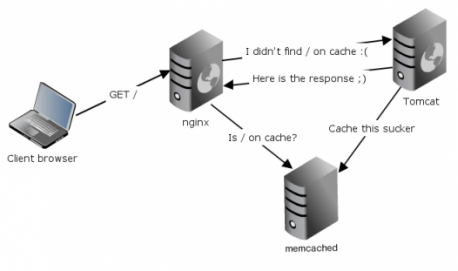
Software architecture
The system uses a client–server architecture. The servers maintain a key–value associative array; the clients populate this array and query it by key. Keys are up to 250 bytes long and values can be at most 1 megabyte in size.
Clients use client-side libraries to contact the servers which, by default, expose their service at port 11211. Each client knows all servers; the servers do not communicate with each other. If a client wishes to set or read the value corresponding to a certain key, the client's library first computes a hash of the key to determine which server to use. Then it contacts that server. This gives a simple form of sharding and scalable shared-nothing architecture across the servers. The server computes a second hash of the key to determine where to store or read the corresponding value.
The servers keep the values in RAM; if a server runs out of RAM, it discards the oldest values. Therefore, clients must treat Memcached as a transitory cache; they cannot assume that data stored in Memcached is still there when they need it. Other databases, such as MemcacheDB, Couchbase Server, provide persistent storage while maintaining Memcached protocol compatibility.
If all client libraries use the same hashing algorithm to determine servers, then clients can read each other's cached data.
A typical deployment has several servers and many clients. However, it is possible to use Memcached on a single computer, acting simultaneously as client and server.
Security
Most deployments of Memcached are within trusted networks where clients may freely connect to any server. However, sometimes Memcached is deployed in untrusted networks or where administrators want to exercise control over the clients that are connecting. For this purpose Memcached can be compiled with optional SASL authentication support. The SASL support requires the binary protocol.
A presentation at BlackHat USA 2010 revealed that a number of large public websites had left Memcached open to inspection, analysis, retrieval, and modification of data.
Even within a trusted organisation, the flat trust model of memcached may have security implications. For efficient simplicity, all Memcached operations are treated equally. Clients with a valid need for access to low-security entries within the cache gain access to all entries within the cache, even when these are higher-security and that client has no justifiable need for them. If the cache key can be either predicted, guessed or found by exhaustive searching, its cache entry may be retrieved.
Some attempt to isolate setting and reading data may be made in situations such as high volume web publishing. A farm of outward-facing content servers have read access to memcached containing published pages or page components, but no write access. Where new content is published (and is not yet in memcached), a request is instead sent to content generation servers that are not publically accessible to create the content unit and add it to memcached. The content server then retries to retrieve it and serve it outwards.
Example code
Note that all functions described on this page are pseudocode only. Memcached calls and programming languages may vary based on the API used.
Converting database or object creation queries to use Memcached is simple. Typically, when using straight database queries, example code would be as follows:
function get_foo(int userid) { data = db_select("SELECT * FROM users WHERE userid = ?", userid); return data; }
After conversion to Memcached, the same call might look like the following
function get_foo(int userid) { /* first try the cache */ data = memcached_fetch("userrow:" + userid); if (!data) { /* not found : request database */ data = db_select("SELECT * FROM users WHERE userid = ?", userid); /* then store in cache until next get */ memcached_add("userrow:" + userid, data); } return data; }
The client would first check whether a Memcached value with the unique key "userrow:userid" exists, where userid is some number. If the result does not exist, it would select from the database as usual, and set the unique key using the Memcached API add function call.
However, if only this API call were modified, the server would end up fetching incorrect data following any database update actions: the Memcached "view" of the data would become out of date. Therefore, in addition to creating an "add" call, an update call would also be needed using the Memcached set function.
function update_foo(int userid, string dbUpdateString) { /* first update database */ result = db_execute(dbUpdateString); if (result) { /* database update successful : fetch data to be stored in cache */ data = db_select("SELECT * FROM users WHERE userid = ?", userid); /* the previous line could also look like data = createDataFromDBString(dbUpdateString); */ /* then store in cache until next get */ memcached_set("userrow:" + userid, data); } }
This call would update the currently cached data to match the new data in the database, assuming the database query succeeds. An alternative approach would be to invalidate the cache with the Memcached delete function, so that subsequent fetches result in a cache miss. Similar action would need to be taken when database records were deleted, to maintain either a correct or incomplete cache.